Have you ever wondered how smartphones alert people with auditory impairments to critical sounds like smoke alarms, baby cries, or doorbells? That is sound recognition technology in action, powered by machine learning (ML).
The tech enables computers to accurately identify and categorize music, human speech, and environmental noises. A recent study found that an AI audio recognition model could correctly identify an impressive 95% of the information typed on a laptop solely based on keystroke sounds. While it highlights potential security risks, sound recognition software is also used for many positive purposes across many fields.
This piece covers what it takes to build a machine learning sound recognition system with estimations based on the case of our AI/ML team. Intrigued? Let us dive into the details!
What Is Sound Recognition Used for in Business?
The variety of sound recognition use cases is expanding each year.
Today, audio recognition software is applied in many industries. Here are some examples of how the technology benefits different areas:
Security: The tech detects and identifies intruders or suspicious activity;
Consumer electronics:Speech recognition software is used in many consumer devices, such as smartphones, voice assistants, and TVs, to control the device or provide information;
Healthcare:AI sound recognition supports the diagnostics of many medical conditions like heart diseases or respiratory problems;
Manufacturing: The technology monitors industrial processes and identifies potential defects;
Transportation: AI-based features recognize sirens, horns, or unusual engine noises, providing alerts or assistance and enhancing driver safety.
As machine learning capabilities evolve, sound recognition software unlocks even more potential applications. Reading this article may spark some innovative ideas in your mind right away. Now, let us pull back the curtain and explore the practical steps of developing an audio recognition app.
Sound Recognition App: Start Safe with the Concept
What does it take to build an artificial intelligence sound recognition system? Of course, every project is unique, with its own set of requirements. We will examine a typical workflow, focus on nuances in ML model training, and discuss timelines and budgets, using a real-life example from CHI Software. A client approached our AI/ML team with the idea of developing audio recognition software using machine learning.
Our first step was to create a proof of concept (POC) outlining our project flow, time and budget estimates, assumptions, and potential risks. While we cannot disclose the full specifics, this breakdown will provide insights into some project features, required team, process, and approximate figures involved.
Project Requirements
In our project, we had a number of requirements and limitations:
Detection speed: We had to detect sound in just a fraction of a second.
Device simplicity: The solution was planned to run on a Raspberry Pi single-board computer.
Data availability: We had less than a thousand examples for each category to teach the model, and we had to get the rest through data augmentation.
It was assumed to be a convolutional model like MobileNet or simpler if it could not fit the time requirements. The input to this model was a spectrogram, and the output FC layer was trained as a classifier. The self-attention mechanism may have been used.
ML Model Training: Balancing Power and Efficiency
Machine learning differs from traditional programming in its non-deterministic nature, meaning that the practices proven effective in other cases may not always be the best option. For example, a model demonstrating state-of-the-art results on one dataset may not necessarily be optimal for solving a specific task in another.
Furthermore, modern state-of-the-art models are complex systems with many parameters, requiring a considerable amount of data and resource-intensive training for high-quality generalization. Sometimes, data collection can be costly or even impossible, and with insufficient data, this advanced model may perform worse than a simpler one.
On the other hand, there is the transfer learning approach, where you can achieve excellent results by fine-tuning a pre-trained model on large open-source datasets, even with a relatively small amount of data.
Moreover, success can often be achieved without training and without data for training. It would help to use open-source pre-trained models that transform input information about objects into standardized vectors (embeddings).
However, these methods may be ineffective for solving a specific task, not necessarily due to a lack of accuracy but possibly due to insufficient inference speed, deployment complexity, scalability, etc.
In such cases,the technology of knowledge distilling can help by co-training a large model with high accuracy and a small, fast model. Therefore, research and experiments are crucial when using machine learning.
Generally, starting with a simple solution carefully selected for the task is better. The next step is to review results, see where they fall short, and figure out what changes you need to make to achieve your goals. The initial solution will serve as a standard for measuring any improvements made as the project progresses.
You have so many options in the AI realm! Let us help you find what fits your business needs
Message our team
ML Model Training
So for our project, a preliminary plan of working with a model included the following stages:
1.Audio data analysis:
extracting optimal input spectral features;
evaluating the importance of other features, such as amplitude envelope;
checking the possibility of building a simpler and faster computational detector that will trigger the neural network to avoid overloading the device with continuous detection;
cleaning signals for further use in data augmentation.
2.Building a simple sound classifier using Mel-Frequency Cepstral Coefficients that will be a baseline for improved models.
3.Model testing: Checking the performance of the classifier on large pre-trained models like Audio Spectrogram Transformer, using them to extract embeddings. In case of good results, such a model can be used for knowledge distilling during the training of the working model.
4.Preparation of augmented data by mixing it with samples from open-source datasets, building and training the working model, and initial optimization to meet the technical specifications.
5.Putting the model to work on the device.
Project Flow
Developing a model is only a part of the whole process. The total flow of sound recognition development follows a sequence of five stages. Let us describe them briefly.
Project preparation: This foundational stage involves researching solutions, collecting data, developing and training the model, and analyzing initial results for performance enhancements.
Optimization: Fine-tuning the model through hyperparameter adjustments, feature transformation, and algorithm experimentation, culminating in a final training round.
Preparing for deployment: Ensuring the model’s efficiency and correctness for specific devices or platforms.
Prototyping: Creating a preliminary model in MATLAB to test feasibility and performance and identify potential issues.
Implementation: Translating the product into executable code, ready for deployment or system integration.
In addition to engineering tasks, the project also allocates time for general activities such as communication, sync-ups, and project setup.
Sound Recognition App: Rough Time and Budget Estimation
Now that we have outlined the project workflow, let us consider the necessary time and budget.
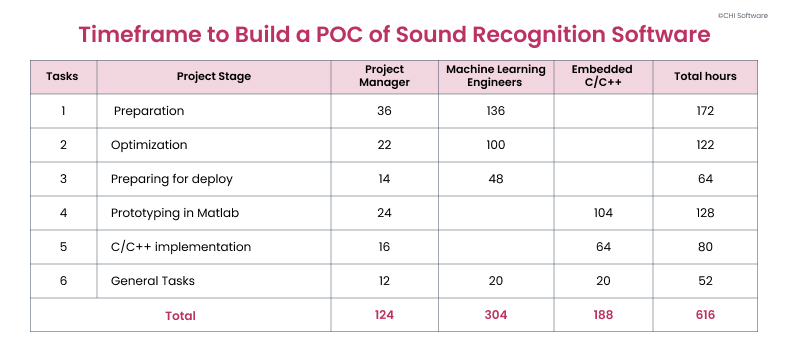
The team for the given project comprises a manager, machine learning engineers, and embedded C / C++ engineers. The table below shows a detailed breakdown of work hours, distributed by a project stage and specialist involved.
You’ll need around 616 working hours or 25-26 working days to finalize a PoC of sound recognition software.
The project duration is estimated to be 2 months, with the possibility of optimization through parallel processes. The total preliminary cost of the POC project is 30,000 USD.
Note that the budget covers solely the ML model and embedded system development, as the model is intended to run locally. We can include additional services depending on the specific project needs, client requirements, or market conditions.
Keep in mind that we operate rough estimates in the preliminary stage. Also, the final budget and deadlines may be changed due to potential risks.
Not all aspects can be foreseen in the initial stages of creating an AI sound recognition app. The potential risks we often highlight to our clients include:
Data quantity: Having a good amount of quality data is essential for any machine learning project. At the outset, we need a certain number of samples for each sound category, say one thousand. However, clients must know that more data might be necessary for further model training.
Workload fluctuation: Precise workload estimation is challenging without initial model training results. Until then, all estimations are provisional, and the actual working hours may vary on both ends.
The Final Chords
Sound recognition technology powered by machine learning is revolutionizing various industries and operations, whether it is enhancing driving safety, ensuring production quality, securing offices from unwanted visitors, or many more. Which scenario applies to your business?
Now that you understand the project flow, it remains the case for small – pick a skillful development team. We are the AI/ML engineers who can help you with that.
CHI Software is a team that turns your bold ideas into reality and helps you explore new avenues. So do not wait any longer. Reach out to us, and let us get started on making your vision a reality!
FAQs
What is sound recognition used for?
Sound recognition identifies and categorizes diverse sounds like alarms, speech, and environmental noises. It's employed in security systems, healthcare diagnostics, consumer electronics, and more.
How does machine learning improve the capabilities of audio recognition software?
ML algorithms improve sound recognition software by enabling it to learn from vast datasets, recognize complex patterns in audio signals, adapt to new sounds, and increase accuracy over time, leading to more reliable and efficient audio recognition systems.
What are the challenges in developing sound recognition software?
Challenges include managing training data quality and quantity, ensuring fast and accurate detection, balancing computational power with efficiency, and adapting the system to different devices and environments.
How much time and money does it take to create an ML-based sound recognition software?
The duration and cost depend on the project's complexity. A rough estimate could be around 2 months and 30,000 USD, but these numbers can change because of project requirements, team expertise, and unforeseen risks.
Do speech recognition and sound recognition software serve the same purpose?
Not quite. Speech recognition software interprets human speech alone, while sound recognition software identifies a wide variety of sounds, including environmental noises, music, and other non-speech audio.
Yurii is a data scientist with a decade of experience and a deep-rooted love for experimental physics, which is now his favorite hobby. He has delved into everything from machine learning to computer vision, and even natural language processing across various industries. When Yurii is not busy cracking data codes, you'll find him enjoying some alpine skiing on the slopes.
Finding the right file shouldn’t feel like a treasure hunt. Yet still, many teams still waste hours digging through contracts, policies, or reports. According to Pew Research Center, almost half of U.S. employees are already turning to AI chatbots to help out with daily tasks at work – and among those who do, 40% say the tools help them move...
Few technologies have changed the way we work as much as cloud computing. The idea first appeared in the 1960s, and six decades later it has become a standard part of business and daily life. The medical sector is among the fastest adopters, and today cloud computing in healthcare is changing how providers store, share, and use patient data for...
Do you know why Enterprise Resource Planning (ERP) systems need chatbots powered by Artificial Intelligence (AI) to truly shine? Read on to learn how ERP AI chatbots make everything a business needs to do work even better. ERP systems are a powerful and vital tool for modern businesses. And as the volume and value of data continues to grow, so...
Make your AI ideas real with the help of our talanted team!
About cookies on this site
We use cookies to give you a more personalised and efficient online experience.
Read more. Cookies allow us to monitor site usage and performance, provide more relevant content, and develop new products. You can accept these cookies by clicking “Accept” or reject them by clicking “Reject”. For more information, please visit our Privacy Notice