Machine learning (ML) is a way for your business to grow revenue and attract more customers. Long gone is the time when AI tools were something out of this world, accessible only to giants like Meta or Apple. Now, innovations are a huge hit, in every sphere imaginable.
The machine learning market is expected to reach 106.52 billion USD by 2030, growing with a 38.76% CAGR. These figures look overwhelming, right? But this growth is fueled by numerous business opportunities you cannot ignore.
Nevertheless, this article is about something other than how great machine learning is. We will talk about a not-so-nice side of things, which is possible hurdles. Innovations do not come easy, and we will not hide this obvious truth.
Together with Olha Kanishcheva, a consulting ML/NLP engineer from CHI Software, we will highlight machine learning challenges and, most importantly, how to solve them. So, let us not waste a minute.
Why Is Everyone Crazy About Machine Learning? The Main Reasons to Use It for Your Business Goals
The Covid pandemic has caused a massive shake in the business world. A lot of companies (CHI Software included) figured out that some traditional operations would no longer work as effectively, especially under uncertainty. Machine learning is a response to the new reality.
Powerful ML algorithms generate insights based on a large amount of real-time data, allowing businesses, among other things, to make predictions about the future. Let us review several game-changing scenarios for ML implementation.
You need to address hundreds of requests at a time.
Suppose you have a B2C business processing money transactions day and night. The number of transactions grows with time, and there is no chance for you to process each payment within seconds. Manual work leads to delays and negative feedback, severely damaging your reputation.
Machine learning can cope with monotonous categorization tasks with no human involvement at all. Your reputation is saved.
You need a cost-efficient alternative to manual tasks.

In some situations, your employees can do the required monotonous work quickly enough, but it eats up too much of your expenses. For example, you need to approve some standard forms or contracts. You can optimize this working process to achieve the maximum result in several minutes, but at what cost? Machine learning, in this case, will be as efficient and will certainly save your budget.
You need to detect typical patterns in a massive data set.
Ronald Reagan once said that information is the oxygen of the modern age. But what will you do if there is too much information with no particular order? Things can get messy, and you will need some help. Machine learning detects hidden patterns and connections invisible to the human eye and gets the most out of the available data.
You need to develop a complex rule-based feature.
Replicating human logic is not that simple, and you will learn that when adding features with complex decision-making capabilities. If you want, for example, your solution to decide whether an email is spam, imagine how many factors will impact the final result.
When writing precise rules becomes problematic, engineers can turn to machine learning. ML-based software does not need well-written patterns – only a solid algorithm extracting patterns automatically on its own.
You need to adapt to a constantly changing environment.
And who does not need that? We are living in an era with a high level of unpredictability. It seems we cannot be prepared for everything, but at the same time, we have to be prepared no matter what. The cost of failure is too high.
Machine learning appears to be a valuable tool for demand forecasting thanks to its abilities to learn on the go and consider hundreds of market trends in real time. You can always remain updated even when client expectations and complex external factors change every year.
What Are the Frequently Faced Issues in Machine Learning Projects and How to Address Them?
When AI and its subsection, machine learning, became a reality, engineers immediately understood that “it is not always rainbows and butterflies”. Development teams must cope with some challenges to make an ML project successful. You surely should know these challenges when considering an innovative solution for your business.
Challenge 1: Discrepancy between business needs and ML project goals
Even though AI and machine learning are trending in the business world, it does not mean they solve any given issue. Businesses should realize that ML development is a never-ending process because algorithms have to learn and evolve.
Are you sure it will bring you tangible results? The earlier you ask yourself this question, the better. Otherwise, here comes the first problem with machine learning: you start your project with no solid reason. Say hi to significant financial risks.
So what should you do?
Luckily, there is no rush when it comes to machine learning projects. You can always consult engineers first and discuss possible risks. Is it worth your investment? If the answer is ‘yes’ go ahead, then.
Before booking your call, identify the issues you want to cover with a machine learning model. Experts will shed light on ML capabilities and specific results you can achieve with your innovative solution.
Challenge 2: Lack of training data

Algorithms need labeled data* to learn, period. There is no other means to make an ML tool efficient. If you do not provide enough information, be ready for inaccurate results and biased predictions. The lack of training data is one of the most popular machine learning problems.
*Labeled data is a set of data samples tagged with labels that add meaning to the context.
You do not necessarily need a lot of images of pears and apples for a child to learn the difference. But teaching an algorithm requires hundreds of examples to distinguish between shapes, textures, and colors. This thirst for data grows with the task complexity and can require millions of data samples.
So what should you do?
This one is simple. Share as much data as you can based on the engineer’s request. Each ML project is unique because it meets individual business requirements. Therefore, you do not need all available data sets – only those that fit the algorithm’s goals. Remember that this point is essential for a smooth project start.
What are the most popular technologies to build indoor positioning systems?
Click to find out
Challenge 3: Insufficient data quality
A lot of info does not necessarily mean that all of it is valid. After collecting data, we need to analyze it. And that is where the shoe pinches. Some data sets, for example, may have missing or outlying values, which means we cannot use them for training. The more abnormal samples we have, the fewer chances we get for proper results, and that is another issue in ML.
So what should you do?
Make sure engineers take enough time for data preprocessing and addressing issues. You can remove outliers altogether while filling missing values with median ones. You can also take necessary measures to structure your data and make it understandable for a machine.
Challenge 4: Non-representative data

Everything seems to be going well. You have enough high-quality data, but your development team still experiences difficulties. Another challenge of machine learning is non-representative samples for model training.
AI in mobile app development: Predictions and trends to check out
Read more
The required data should cover as many scenarios as possible. Otherwise (yes, you get it right), your system will provide inaccurate results. Plus, a small amount of data leads to a significant amount of sampling noise (i.e., unrepresentative information) and, next, to sampling bias.
So what should you do?
Ensure that all the data you collect comes from the right department and directly relates to project goals. Engineers can provide you with instructions about what data exactly is required for the maximum benefit.
Challenge 5: Irrelevant data features
Training data has unique characteristics that can either harm your model or bring you the desired outcomes. It is all about the balance. A high number of unwanted data features is a quite common challenge in machine learning. Let us consider an example.
Your model must be able to predict the number of calories a person should consume to lose weight. The parameters you have at hand are gender, weight, height, age, and residency. What do we see from this example?
- The residency parameter is not necessary to help someone count calories;
- The weight and height parameters are used to calculate a more important feature – Body Mass Index (BMI);
- We can add more impactful features, such as time dedicated to physical activity daily or weekly.
Voice Command Revolution: A Step-by-Step Guide to Developing Voice Recognition Apps
Read more
So what should you do?
The example shows that each feature should be considered separately and optimized when necessary. This process is referred to as feature selection, and it helps decrease the computational powers in modeling and improve the model’s performance. Feature selection techniques should be picked individually according to the project needs and requirements.
Challenge 6: Overfitting of training data
We, humans, love to generalize our knowledge. It is convenient to think that if it happens to you once, it happens all the time to other people. If you, let us say, visit one expensive restaurant in Rome, it is tempting to conclude all restaurants in Rome are rather costly. Algorithms are arranged in a similar way.
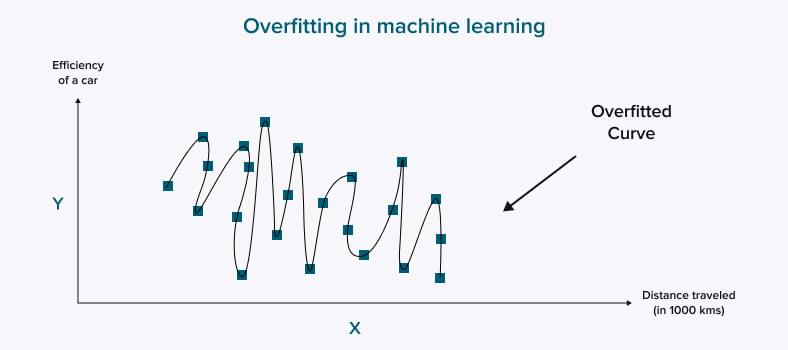
Suppose you provide your model with many samples of one item (for example, images of apples) and add a smaller number of other items (oranges, bananas, and peaches). In that case, your model will more likely classify bananas or oranges as apples. It happens because there are too many apples “in your basket”.
The phenomenon (and a challenge of machine learning projects) when your model tends to overgeneralize information is called overfitting. An overfitted solution can make inaccurate predictions because it is trained on a lot of noisy data.
So what should you do?
There are several steps to take:
- Collect more training data for each data input;
- Get rid of noisy data (errors and outliers);
- Apply regularization approaches (Lasso regression or Ridge regression);
- Use K-fold cross-validation to evaluate predictive models.
Challenge 7: Underfitting of training data
We call a model underfitted when it is too simple to capture potential complexities, so it performs poorly both on training and testing data sets. Just like overfitting, underfitting is among the problems in machine learning, leading to inaccurate results. This issue happens if there needs to be more data or when we build linear models using non-linear information.
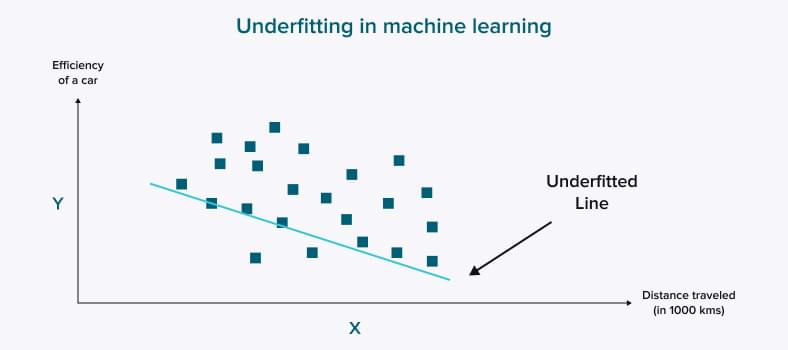
So what should you do?
Here are the steps to take:
- Increase the training time;
- Add more data features;
- Remove noisy data;
- Increase model complexity.
Challenge 8: Data privacy & security
At this point, you probably realize that data means everything for ML projects. But it is also a cause for constant concern. Securing so much information is challenging and extremely important at the same time.
So what should you do?
Data privacy is a complex task requiring a diversified approach. This is what we suggest undertaking:
- Make sure that all data is under protection. It usually means you apply robust encryption methods and take care of reliable data storage. You must also remember about the people who access available data. Only a few specialists need this data to finalize their daily tasks.
- Be transparent when gathering sensitive information. If your model needs it to provide accurate results, let people know what data will be collected and for what purposes. Also, users should have the option to refuse to provide their sensitive data.
- And lastly, collect only the data you need. This point seems obvious, but nonetheless, keep in mind that too much data may result in a high risk of breaches and wasted resources. Remember, it is all about the balance.
Challenge 9: Lack of talent
Even though machine learning is all the rage now, it does not mean any developer can manage this innovative technology.
A typical ML project includes finding relevant data, training an algorithm, and monitoring its performance. To accomplish it successfully, you need a team of data scientists and some more properly trained specialists. You probably think it is rather costly, and you are absolutely right. But this is not all. Even finding such a team requires remarkable efforts.
So what should you do?
If you are not ready to start a new department within your organization, you can use an off-the-shelf solution or outsource development efforts. Each option has its pros and cons, and every organization should decide individually what to choose.

Ready-made products have already done all the hard work, but their capabilities are somewhat limited. If you aim to build an ML solution with complex logic, you will definitely need additional help from a team of experts.
In any case, you should make the final decision based on the goals of your project. Only with a clear vision in mind can you discuss software requirements with vendors and build a detailed project roadmap.
Final Thoughts: Establish Project Goals and Prepare Your Data
The machine learning niche is relatively new and raises many questions among engineers and entrepreneurs. But one thing is certain: it is one of the most promising technologies to boost business growth. A lot of opportunities are already waiting behind the curtains of possible challenges.
To minimize problems with machine learning, you must establish your goals and prepare sufficient relative data. This is it. ML engineers and data scientists will help you with the rest.
What we love the most about ML projects is that they are never the same. Each business is unique, and so is the final result. Do you want to know what outcome is waiting for your business? It is time to start then. One conversation is enough to build a rough roadmap for your project. It is free – just let us know what idea is on your mind.
About the author
Olha boasts a decade-long journey in NLP, currently serving as a researcher at Jena University and a Consulting ML/NLP Engineer at CHI Software. Her expertise extends to various realms of NLP, including text summarization, named entity recognition, and keyword extraction. Olha's Ph.D. thesis explored knowledge representations and information retrieval in librarian systems.
Rate this article
24 ratings, average: 4.5 out of 5


