As of 2025, the world generates around 402.7 million terabytes of data every day — and 90% of most data has been created in just the past few years. These figures mean a new paradigm: for any company that works with data the importance of data engineering is undeniably at the center of your business strategy. Naturally – how else will you keep up with constantly changing market trends?
This article will explore the fundamentals of crafting an effective data engineering strategy, whether this niche is new for you or you’ve been here for a while.
We’ll start with specific business benefits you can expect from a well-built strategy and explore how to implement it in your working routine, while covering the most common challenges that await you. And when you get stuck, you’ll also get to know how expert data engineering services can help.
Dont't waste your time – discuss your data engineering plans with our team!
Any data engineering strategy starts with you. What business goals do you want to achieve with data engineering, and what data sources would you like to use? These are the questions you need to answer when looking for a technical vendor;
Based on our experience, an efficient strategy allows you to achieve 40%-50% faster data processing;
Your data engineering efforts will truly shine using machine learning models and natural language processing algorithms – we know because we’ve implemented them for our client’s data classification tasks.
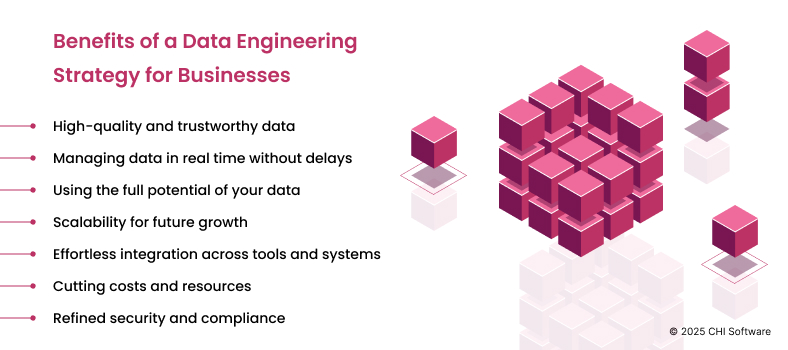
How a Solid Data Engineering Strategy Can Benefit Your Business
Data strategy and engineering can make routine business processes more efficient and meaningful.
Even though there’s a lot of talk about a data-driven approach to business, not everyone fully grasps its importance in helping a company gain the upper hand on the competitive market. Let us walk you through the most impactful business benefits, explaining why data engineering is important.
1. High-Quality Data That You Can Trust
Nobody likes working with messy, outdated, or incomplete information. So how can you fill in the gaps? And is it even possible? With a good data engineering strategy, your information is clean and always up to date, which will help you generate relevant reports and minimize bad decisions based on flawed information.
2. Managing Data in Real Time Without Delays
Have you ever had to wait for hours for a report to load or struggled in your work day with tediously slow queries? We’ve all been there! A well-built data pipeline speeds up processes so teams can get the insights they need in real time (or at least way faster than before).
AI and Data Engineering: A Game-Changing Collaboration
Read more
3. Using the Full Potential of Your Data
Your company likely generates and collects vast amounts of data every day. But without a proper data engineering strategy, this goldmine of information might as well be a pile of digital dust. Having a solid strategy helps you organize, process, and analyze this data effectively, turning piles of information into actionable and trustworthy insights.
4. Scalability for Future Growth
Your business isn’t static, and your data shouldn’t be either. A strategy for data engineering helps your system navigate increasing data volumes without crashing or slowing down.
5. Effortless Integration Across Tools and Systems
It’s likely that you use multiple platforms to handle your daily tasks: CRMs, ERPs, marketing tools, analytics software – the list goes on and on. A well-thought-out strategy helps connect these systems, allowing your data to flow smoothly between software tools and company departments. The era of data silos is coming to an end!
The True Cost of Data Silos & How to Eliminate Them
Read more
6. Cutting Costs and Resources
Inefficient data management costs your business money. Whether it’s bloated storage costs or expensive processing power wasted on low-quality or irrelevant data, a strategic approach helps you optimize resources and save money in the long run.
7. Refined Security and Compliance
Data breaches and compliance fines are no joke. Best practices in data engineering include proper governance, encryption, and access control, keeping your data safe and helping you to meet industry regulations like GDPR or CCPA – we’ll cover the security aspect in more detail in the next chapter.
But regardless of all these fantastic benefits, data engineering strategy implementation is by no means a one-size-fits-all solution – it’s not something you can simply buy or upload to your device. You need to buildit in a way that aligns with your business goals and addresses specific workflow bottlenecks. Do you want to discuss it in more detail? Our expert team is your best advisor.
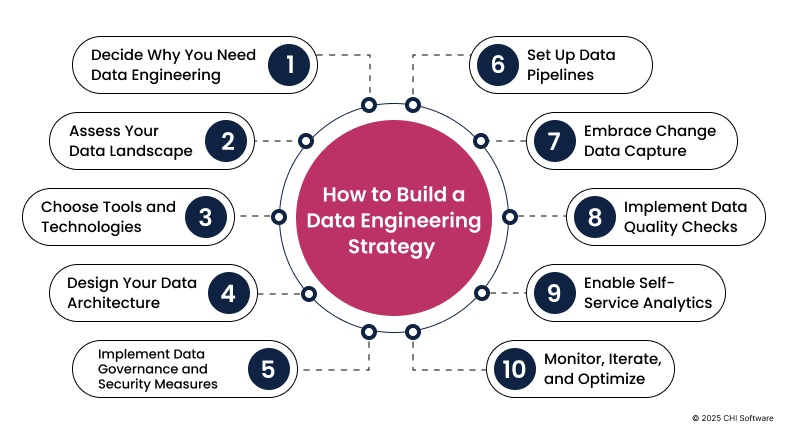
How to Build a Data Engineering Strategy in 10 Steps
Strictly speaking, you don’t have to build a data engineering strategy on your own, but your participation is essential because your tech team will work with your internal data. Here’s an overview of what you need to know and do as a business manager.
These steps illustrate a general approach to building a data engineering roadmap.
1. Decide Why You Need Data Engineering Now
Before jumping into the technical nitty-gritty, step back and outline what you want to achieve.
Are you looking to improve your team’s decision-making? Streamline operations? Or perhaps you’re aiming to enhance customer experiences? You don’t need data engineering just because it’s a hot topic – it’s formulating specific goals and acting on them that will move you further.
Your business needs will shape your entire data strategy and engineering approach, so make sure project requirements are crystal clear and necessary from the get-go.
Transforming Data Life Cycle Management with Generative AI
Read more
2. Assess Your Current Data Landscape
For the second step, you will need to take stock of what you’ve got. Conduct a thorough inventory of your data sources, systems, and processes. This step will help you and an engineering team identify gaps and opportunities in your current setup. You might be surprised by the hidden gems of data that are already in your possession!
These are the data types we look at when developing a data engineering roadmap:
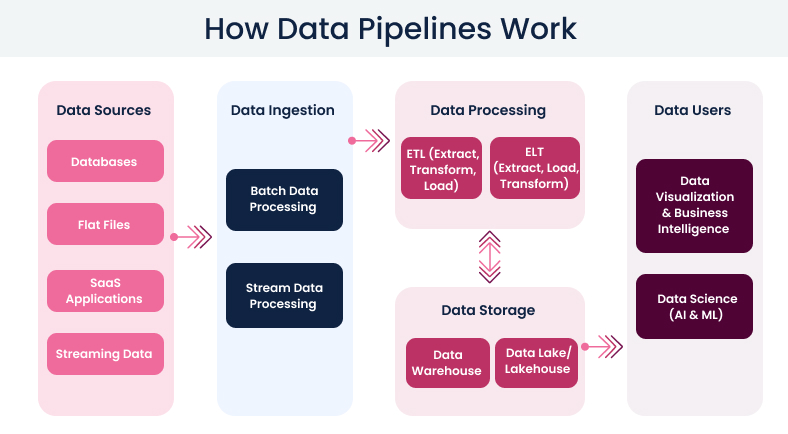
List of data sources: databases, APIs, third-party services, spreadsheets, etc.;
Current data storage and processing infrastructure:cloud, on-premises, or hybrid;
Existing data pipelines and workflows: ETL/ELT processes, batch vs. real-time processing, etc.;
Data formats and structures: schemas, JSON, CSV, relational databases, etc.;
Access control and security requirements: who can access what data and under what conditions;
Known data quality issues: duplicates, missing values, or inconsistencies.
3. Choose the Right Tools and Technologies
Here’s where the fun begins! Selecting the right tools for the job is critical for implementing data engineering best practices. Popular tool examples among our data engineers include:
Apache Spark for large-scale data processing,
Apache Kafka for real-time data streaming,
Airflow for workflow management,
Snowflake or BigQuery for cloud data warehousing.
Remember, the best tools are the ones that align with your specific needs and objectives – so don’t hesitate to ask your engineering team why they’ve picked this or that software.
With your goals set and tools chosen, it’s time to create a blueprint of your data architecture. At this stage, you and your team will decide how data will flow through your systems, from ingestion to storage and processing.
Drafting a data architecture requires time and attention to detail, so allow your technical team to focus on this step as much as needed. Partnering with a big data development company can be a huge bonus if you have some revolutionary changes on your mind. In the end, it is like the foundation of a house – defining how strong and how long it will stand for.
Big Data Processing: Methods, Tools & Strategies
Read more
5. Implement Data Governance and Security Measures
We’re sure we don’t have to explain the importance of security measures as a separate step among best practices for data engineering infrastructure. If you poorly manage your data or fail to maintain security protocols, you will face inefficiencies, compliance risks, and many other unpleasant consequences. Here’s our advice on this point.
How to Protect Your Data and Minimize Security Risks
Data Ownership and Responsibilities
Define who is responsible for managing and maintaining different data assets.
Access Control and Permissions
Implement role-based access control (RBAC) to restrict data access based on user roles.
Data Classification and Sensitivity Levels
Categorize data according to its confidentiality and define management rules (e.g., public, internal, restricted, or highly sensitive data).
Compliance and Regulatory Requirements
Align your data with GDPR, CCPA, HIPAA, or other relevant regulations.
Data Quality Standards
Establish rules for data accuracy, completeness, and consistency.
Security Measures
Encrypt sensitive data, monitor access logs, and enforce multi-factor authentication.
Audit and Monitoring
Continuously track data usage and detect anomalies with logging and auditing tools.
6. Set Up Data Pipelines
Now, we’re getting into the backbone of data engineering. Data pipelines facilitate information flow from various sources to storage and processing systems without interruptions. Skipping this step means risking delays, data loss, and inconsistencies that can damage the entire data management workflow.
Setting up efficient pipelines in a data engineering strategy requires several measures.
At this stage, we usually focus on:
Reducing potential bottlenecks by choosing the optimal pipeline architecture (streaming vs. batch processing);
Eliminating manual data work by setting up pipelines that simplify routine transfers;
Making sure that our pipelines handle increasing data volumes when our client’s business grows;
Implementing checks to filter out errors, duplicates, and inconsistencies before data reaches analytics tools;
Using logging, alerts, and failover mechanisms to prevent pipeline failures.
Our go-to tools for this work include Apache NiFi and Talend, which help automate and simplify data integration across all business departments.
7. Embrace Change Data Capture (CDC)
CDC in data engineering allows our team to track and capture changes in your data sources immediately, guaranteeing your data warehouse or data lake always has the most up-to-date information. This step is essential for real-time analytics, reporting, and decision-making – all the reasons why businesses would opt for high-quality data engineering.
Our team uses Debezium, Striim, and AWS DMS, integrating them with your existing infrastructure. Depending on your architecture, we can implement log-based, trigger-based, or polling-based CDC to match your business needs best:
Log-based CDC is best for large-scale data pipelines with high transaction volumes (think financial transactions or e-commerce);
Trigger-based CDC is more suitable for smaller-scale databases;
Polling-based CDC is the right choice if real-time processing is not critically important for your business goals.
8. Implement Data Quality Checks
Quality data is the lifeblood of data engineering principles. After all, how can you trust your processes if you’re unsure what’s happening with your datasets?
These are the data quality practices our team actively uses in daily work and recommends keeping in mind:
Setting automated validation rules that define what is an anomaly for your data set (e.g., negative sales figures or invalid email formats);
Verifying schema consistency;
Detecting outliers or unexpected trends with machine learning models;
Setting up alerts for data failures and automating data correction.
Our tools for quality assurance include Great Expectations, Deequ by AWS, dbt Tests, and AI-driven tools like Monte Carlo and Soda.
How to Build Data Infrastructure: 7 Key Steps & Tips
Read more
9. Enable Self-Service Analytics
What will you do with all the powerful insights and opportunities data engineers provide? It’s time to consider the instruments that your team will use to simplify data processing and analytics.
Many of our clients rely on Tableau, Power BI, Looker, or Metabase – and there’s a good chance you’re already using one of these platforms. With the proper setup, these tools can provide you with even greater value.
Once you’ve selected the right tool and established strong data governance (see step five), here’s what we recommend next:
Use curated data marts, semantic layers, and pre-aggregated data sets to simplify access;
Set up scheduled data updates so your team works only with the latest information;
Help your non-technical employees fully embrace the technology by providing workshops and easy-to-grasp documentation.
10. Monitor, Iterate, and Optimize
Optimization might seem like a final touch – but in data engineering, it’s an ongoing process. Your work with data is never truly “finished” – it evolves as your business needs continue to evolve.
At this stage, focus on:
Continuously monitoring your system’s performance, errors, and potential issues,
Gathering feedback from your employees,
Iterating and optimizing existing flows and tools.
Understanding how to implement a data engineering strategy and ensuring continuous optimization will keep you ahead as the data world evolves.
Addressing Common Challenges in Data Engineering Strategies
Implementing a modern approach to data engineering is no walk in the park. But the better you prepare, the fewer unpleasant surprises will await you later in the process.
This section will introduce you to the most common obstacles in data strategy and engineering and how to cope with them.
Considering these challenges in your data engineering roadmap will help you avoid common business issues before they happen.
Scalability and Performance Concerns
As the volume of your data grows, your infrastructure must handle the load. In this case, scalability is crucial, mainly when you deal with a big data engineering strategy – so we strongly recommend delegating this task to cloud platforms.
The well-known Amazon Web Services (AWS) or Microsoft Azure can be a perfect choice for flexible scaling. These platforms offer AWS Glue or Azure Data Factory, which can help you process and analyze large datasets. Whether you’re working with cloud computing or data science, these tools will help you grow without fuss.
Another great benefit of cloud platforms is their flexible budgeting. You can scale your business up or down based on your needs, and your spending will change accordingly.
Integration of Legacy Systems
Many organizations struggle with integrating legacy systems into their modern data architecture. These older systems often use outdated technologies and data formats, making it challenging to incorporate them into your data engineering strategy.
To overcome this challenge, consider using ETL (Extract, Transform, Load) tools designed explicitly for legacy system integration. Informatica PowerCenter or IBM InfoSphere DataStage can help you extract data from legacy systems and transform it into formats compatible with your data infrastructure.
Balancing Cost and Performance
Implementing modern data strategies in data engineering can be costly, particularly when managing big data. Here is how you can strike the right balance between performance and cost-effectiveness:
Optimize data storage:
Classify data based on usage: Store the hottest (most frequently used) data in high-performance environments while keeping rarely used data in lower-cost storage like Amazon S3 Glacier or Azure Blob Storage Archive;
Delete or archive obsolete data: You can automatically remove outdated information or move it to budget-friendly storage.
Pick cost-effective data processing tools:
Distributed storage and processing: Apache Hadoop, Amazon S3, Google Cloud, and Azure Data Lake;
Cloud-based analytics: Google BigQuery, Snowflake, or AWS Athena;
Serverless solutions: AWS Lambda, Google Cloud Functions.
Regularly conduct performance audits and cost analysis:
Track resource utilization with Datalog, Prometheus, or AWS Cost Explorer;
Optimize SQL queries to reduce computing time;
Set up auto-scaling for cloud resources to prevent over-provisioning and cut costs.
All these challenges are not new for CHI Software. Moreover, we tackle them proactively during our projects – not to mention, the skill gap can be another challenge for your team. So if you notice a lack of expertise, you know whom to turn to for advice.
Choosing the Right Data Engineering Partner: CHI Software’s Expertise
Choosing a data engineering vendor can be quite a difficult task, especially when you have to manage strict deadlines or specific industry issues. Many teams can tell you about their technical qualifications, but CHI Software has gone further. Our main goal is to align our expertise with our clients’ business goals. After all, what’s the point of discussing algorithms if they don’t serve your specific needs?
Our AI and machine learning department started its work in 2017, and since then, we’ve grown into vetted experts in generative AI, data engineering, and computer vision. But, most importantly, we’ve partnered with businesses of different sizes and industries. Here’s what we have to share.
Enhancing Business Intelligence and Reporting for a Food Tech & Hospitality Business
One of our US-based clients is famous for offering a variety of cuisines across delivery, takeout, and dine-in. Along with having a customer base, the company also has a lot of partnerships with chefs and restaurants. In these circumstances, managing data wisely is an absolute necessity.
In this example of data engineering strategy, CHI Software’s tasks were to improve BI reporting and ETL processes, as well as provide real-time financial insights and scalability.
Best practices in data engineering helped our client achieve 40% faster data processing and real-time financial visibility.
Strategic Approach
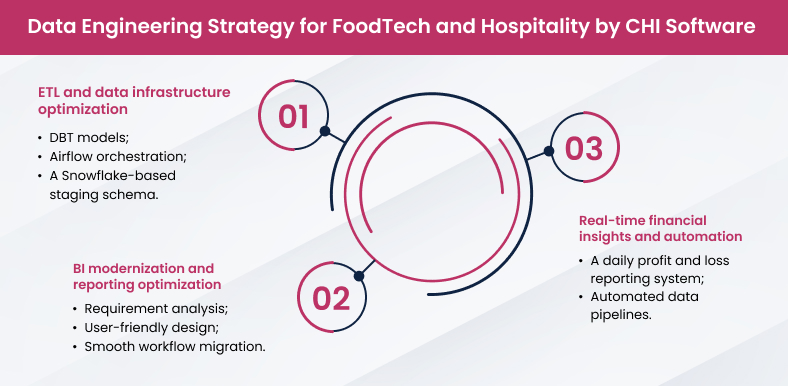
BI modernization and reporting optimization
Our client had been relying on Looker for BI reporting, but needed a more flexible and powerful tool. We led a strategic migration to Power BI, focusing on:
Requirement analysis to bridge reporting gaps and enhance visualizations;
User-friendly design for deeper insights and easier adoption;
Smooth workflow migration, focusing on business continuity.
ETL and data infrastructure optimization
Scaling data operations required a robust and structured ETL pipeline. Our team implemented:
DBT models to improve data transformation, cleansing, and deduplication;
Airflow orchestration to automate ETL processes, cutting manual work;
A Snowflake-based staging schema for better organization and retrieval of raw and refined data.
Real-time financial insights and automation
The company struggled with delayed financial reporting, making fast decision-making difficult. We built:
A daily profit and loss reporting system, giving stakeholders instant access to key financial metrics;
Automated data pipelines that provide continuous updates and eliminate manual errors.
With these strategic improvements, the company gained real-time financial visibility, 40% faster data processing, and a scalable ETL architecture that is ready for growth. The transition to Power BI helped decision-making with more precise and actionable insights.
Efficient Data Pipeline and AI-Based Insights for Investment Research
Our client, headquartered in Portugal, helps identify promising startups in Europe and North America using natural language processing (NLP). Since their approach to stock market research is truly innovative, they prioritize powerful machine learning algorithms and seamless data flows.
Data for algorithms comes from various APIs, and the approach varies by country – different rules mean different data, so the machine learning model adapts accordingly. We aimed to fully automate data collection and ingestion from every valuable source.
A well-built strategy for data engineering helped our client automate data ingestion and simplify data classification.
Strategic Approach
Automating data workflows
Manually pulling data from multiple APIs was slowing down our client’s processes. Our team fixed that by:
Building an end-to-end ETL pipeline to automate data extraction, transformation, and loading;
Integrating real-time insights into Google Sheets so analysts could access fresh data instantly.
AI-powered data classification
The company needed a more accurate way to categorize startups. CHI Software’s solution:
SetFit ML models to classify startups across German, English, and French;
NLP algorithms to refine categorization and improve data relevance.
Scalable and future-ready architecture
To provide our client with long-term flexibility, we implemented:
Apache Airflow (Google Composer) for automated workflow orchestration;
Google Cloud Run for API data scraping and preprocessing;
Google BigQuery for scalable data storage and reporting.
As a result, the company sped up data processing by 50%, making investment analysis much faster. With data ingestion fully automated, manual data entry became a thing of the past. Smarter classification even led to more accurate insights, while a scalable setup made it easy to integrate new data sources.
Conclusion
Best practices in data engineering come in many forms – as you’ve just seen. Efficient pipelines, scalable architecture, and automated data workflows require a strategic approach.
The ten steps we’ve covered have helped CHI Software complete many projects, and we’re happy to discuss your data challenges and potential improvements.
They say the hardest part of a new project is getting started – we’ll make it easy for you. Share your thoughts and ideas in the contact form, and we’ll get back to you soon. Your data (and your bottom line) will thank you.
FAQs
How can CHI Software help with data engineering?
Our team makes your data faster, cleaner, and more useful by:
- Building and optimizing data pipelines: Automating ETL processes to create reliable and smooth data flows;
- Strengthening business intelligence: Integrating Power BI and BigQuery for better reporting and decision-making;
- Providing data scalability: Designing architectures that can react to your business changes so you're always ready for more data;
- Implementing real-time analytics: Giving you up-to-the-minute insights to help you make informed data-driven decisions.
If your data feels like more of a headache than a resource, we'll turn it into a competitive advantage.
How do I know if my company needs a data engineering overhaul?
If any of these sound familiar, it's time for an upgrade:
- Slow and outdated reports: If generating reports takes hours or days, your data pipeline requires some refinement;
- Manual data processes: Still copying and pasting from spreadsheets? It's time to automate your tasks;
- Scalability issues: If your data infrastructure struggles to manage more volume, it's holding your business back;
- Inconsistent or inaccurate data: Poor data quality leads to unreliable insights, which means faulty business decisions;
- Missed real-time opportunities: It might be too late to act if you can't access real-time insights.
Why does my business need a data engineering strategy?
A strong data engineering strategy helps you stay ahead, not play catch-up. Here's why it matters:
- Easier and efficient decision-making: Get insights that help you grow instead of relying on guesswork;
- Lightning-speed operations: Cut down on human errors by delegating routine repetitive tasks to technologies;
- Being ready for data growth: Help your data infrastructure handle future growth without constant fixes;
- Better data quality that brings results: Clean, structured, and reliable data leads to more accurate business insights.
What challenges do companies face without a proper data strategy?
Without a well-thought-out data strategy, businesses often struggle with:
- Data silos: Information is scattered across different systems, making it hard to get a clear picture;
- Slow and unreliable analytics: Reports take too long to generate, and the numbers might not even be correct;
- High operational costs: Inefficient data management leads to wasted resources and unnecessary expenses;
- Missed growth opportunities: Without real-time insights, you can't react quickly to market changes;
- Security and compliance risks: Poorly managed data increases the risk of breaches and regulatory issues.
How long does it take to implement a data engineering solution?
The final time estimation depends on your business size, data complexity, and goals, but here's a rough breakdown:
- 2-4 weeks: Quick optimization tasks, such as BI improvements, minor ETL fixes, and automation tweaks;
- 1-3 months: Medium-scale upgrades, such as data pipeline automation, cloud migration, or improved reporting;
- 3-6+ months: Large-scale transformations, which may include complete data architecture redesign, AI-driven analytics, and enterprise-wide data integration.
Sirojiddin is a seasoned Data Engineer and Cloud Specialist who’s worked across different industries and all major cloud platforms. Always keeping up with the latest IT trends, he’s passionate about building efficient and scalable data solutions. With a solid background in pre-sales and project leadership, he knows how to make data work for business.
Yana oversees relationships between departments and defines strategies to achieve company goals. She focuses on project planning, coordinating the IT project lifecycle, and leading the development process. In their role, she ensures accurate risk assessment and management, with business analysis playing a key part in proposals and contract negotiations.
Unless you’ve been living under a rock, you’ve probably noticed by now how many platforms, online stores, and apps are adopting AI chatbots – and it’s no wonder why! These powerful AI-driven bots are no longer just digital assistants: they are quickly becoming the beating heart of business. Modern chatbots are not limited to customer service – they can close sales,...
ChatGPT creates a buzz! The solution gained 100 million users two months after its launch, bringing public attention to the generative AI niche. Business is enthusiastic about the benefits of various ChatGPT use cases too. 97% of business owners believe the technology can improve at least one aspect of their business, and 90% expect benefits from ChatGPT utilization. How can...
Despite being around for a while, cloud computing is still a buzzword due to its versatility. It doesn’t matter whether you are interested in developing solutions, training AI models, or expanding your business operations — cloud computing can do it all. The cloud is a great way to work with data. Data science, as you can guess, benefits greatly from...
We use cookies to give you a more personalised and efficient online experience.
Read more. Cookies allow us to monitor site usage and performance, provide more relevant content, and develop new products. You can accept these cookies by clicking “Accept” or reject them by clicking “Reject”. For more information, please visit our Privacy Notice