In 2025, combining AI and big data development will not be an optional novelty – they will be essential for just about every industry you can think of. According to Statista, the automotive, aerospace, and telecommunications industries have already reached 100% adoption.
Other sectors are not far behind: IT and insurance – 97%, financial services – 95%, and healthcare – 92%. These numbers make it loud and clear that companies are rapidly adopting data-driven solutions to lead the market.
In this article, we will show you how working with big data changes a company’s operations to help them stay one step ahead of the competition. Plus, we’ll share some go-to big data tools and techniques that we recommend using to make data work for your goals.
Why wait any longer? Consult our experts right away to enter the big data game.
Let's connect
Article Highlights:
- Data-driven companies are 19 times more likely to be profitable — but without the right tools to handle big data, much of that potential remains untapped;
- With real-time data pipelines – automated systems created by data engineering experts – you can track every customer action as it happens and instantly adjust strategies to increase customer engagement;
- Thanks to CHI Software’s big data processing improvement, our client experiences 2x faster data processing, 50% less manual work, and operating the most up-to-date figures.
The Big Data Challenge: Why Processing Matters
Businesses today have access to more information than ever before. Every click on a website, customer order, or comment on social media increases the amount of data. But the truth is, it’s not enough just to have it – you should know how to process big data to make smart decisions. This is where the real challenge – and opportunity – comes in.
Let’s look at a few of the most common business problems and how big data techniques can help solve them.
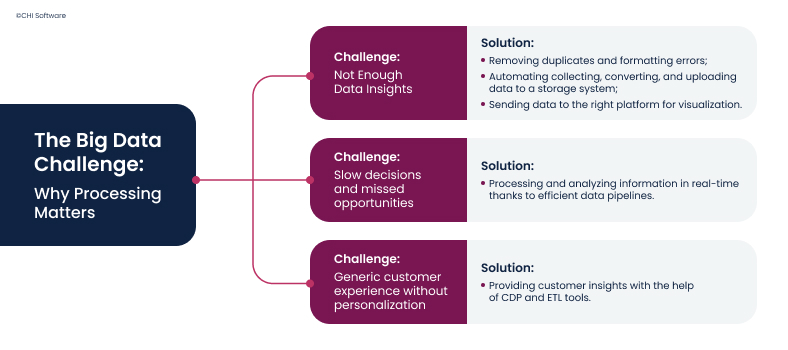
Big data processing can help you address common (and quite annoying) business issues.
Too Much Data, Not Enough Insight
Data can be the key to success if you know how to use it: data-driven companies are 19 times more likely to be profitable. However, not every company understands what to do with the data they collect.
The first challenge is the sheer volume of data and its structure. Companies usually deal with both structured and unstructured data in huge amounts. But with big data management and processing, it all comes together seamlessly. Unlike traditional data processing techniques, a proper big data architecture can:
- Clean up the data: Big data tools automatically detect and remove duplicates and formatting errors, filling in missing information where possible;
- Structure data sets: In many real-world scenarios, for example, when working with big data in logistics, you deal with massive amounts of unstructured data from various sources. Modern big data tools and techniques can automate your collecting, converting, and uploading data to a storage system;
- Manage big data: After cleaning and structuring, the data will be sent to the right platform, from which data visualization tools can produce easy-to-read dashboards, graphs, and reports.
Before implementing advanced big data solutions, businesses often need to establish a solid foundation with data modeling services, ensuring data structures align with both business logic and analytical goals.
AI and Big Data: How They Complement Each Other
Read more
Slow Decisions, Missed Opportunities
When it comes to business, timing is everything. If data arrives late or takes hours (or even days) to process, your team can end up making decisions too late.
Fortunately, big data processing can change all this: it allows companies to process and analyze information as it comes in. This sort of real-time assessment is possible thanks to data pipelines, which provide a continuous flow of data from various sources (e.g., websites, applications, or sensors) into your analytics tools, where it is instantly sorted, analyzed, and acted upon.
With the right real-time data pipeline development in place, you can track every click or product view on the site as it happens. Engineers can design the system to identify user behavior patterns. For example, when customers repeatedly view the same product, the system can trigger the corresponding actions in real time like offering a personalized discount or recommending similar items.
Data Engineering Strategy: Benefits, Challenges & Best Practices
Continue reading
Generic Customer Experience
Today, generic marketing just doesn’t cut it. Customers expect a fast, relevant, and personalized experience at every touchpoint. But if they don’t get it, they’re likely to move on to a competitor who “gets” them better. In fact, 80% of customers have switched brands because of poor customer experience.
Big data solutions help you bridge this gap, giving you a clear picture of what your customers want, when, and how they prefer to interact with you. Your team can get access to these insights with the help of well-established CDP (Customer Data Platform), ETL (Extract, Transform, Load) tools in addition to your existing systems.
Choosing the Right Tech Stack: Tools That Make a Difference
Choosing the right big data tools for your architecture is about finding solutions that fit your needs, workloads, and goals. Let’s look at the key areas of big data processing techniques that can truly make an impact.
Batch and Stream Processing
Let’s start with how your data moves. The first question you should ask yourself is: Do I need real-time insights, or can they wait? The answer will determine your choice of approach to data architecture.
| Area |
Best for |
Tools |
| Batch Processing |
Large-scale, non-time-sensitive tasks (e.g., end-of-day reports, trend analysis). |
Hadoop: Uses MapReduce for distributed data processing; it’s ideal for large, non-time-sensitive tasks.
Spark: In-memory processing for faster batch processing; integrates libraries for SQL, streaming, ML, and graph processing. |
| Streaming Processing |
Real-time data analysis (e.g., personalized customer messaging, live data insights). |
Apache Flink: Stateful, event-driven processing; it’s scalable and fault-tolerant, integrates with Kafka, HDFS, and Amazon S3 for real-time analytics. |
Smart Storage Choices
Once you’ve got all the data, you will need to find a secure, scalable, and affordable storage solution.
| Area |
Best for |
Tools |
| Cloud Storage |
Businesses that need scalable, flexible, and durable data storage solutions. |
Amazon S3: Cloud object storage with high durability (99.9% uptime) and easy integration with other tools.
Delta Lake: Enhances data lakes with time travel, data quality enforcement, and upsert capabilities. |
| On-Premises Storage |
Businesses in regulated industries that require full control over security and compliance. |
HDFS: High-performance distributed storage breaks files into chunks across multiple nodes with fault tolerance and single-write, multiple-read capabilities. |
Creating Intelligent Data Pipelines
Now here’s where the fun begins. Once your data is collected and stored, you need to deal with data ingestion — in other words, moving data through your systems to make it useful. This is where ETL integration and data pipeline development come into play.
Let’s say you want to extract customer data from your website, clean it up, enrich it with sales data, and move it into a dashboard. Doing this manually can be slow and prone to errors.
Instead, CHI Software’s engineers recommend using big data tools like Apache NiFi, Apache Airflow, and DBT (Data Build Tool), which can automate the entire process.
- NiFi helps your team track the data flow from start to finish – showing where each piece of data comes from, how it’s transformed, and, most importantly, allowing you to visualize the entire process.
- Apache Airflow, on the other hand, works like a traffic controller, helping you organize tasks by creating DAGs (Directed Acyclic Graphs) and managing task dependencies, retries, alerts, and scheduling.
- DBT helps analysts create modular SQL models with built-in features for testing, documentation, and version control.
To streamline the entire data lifecycle, many companies turn to DataOps services that can automate pipelines and accelerate deployment.
Machine Learning and AI
Once your data is clean and structured, you can train models on large datasets. Want to predict which users are most likely to grow your customer base? Machine learning, along with AI, uses advanced methods to make this happen:
- MLlib (built into Apache Spark) trains models for classification, regression, clustering, or even recommender systems (collaborative filtering) on massive data sets;
- TensorFlow is perfect for image recognition, natural language processing, or speech analysis. TFX, which is built on top of TensorFlow, takes care of the post-training steps, checking data cleanliness and confirming that the model is good enough for safe deployment;
- SageMaker gives you everything in one place: data labeling instruments, model building and training environments, built-in algorithms or support for your code, and built-in tools for monitoring, scaling, and retraining.
Strategies for Scalable and Cost-Effective Big Data Processing
Big data processing techniques help businesses solve a wide range of challenges. But to get the most out of them, you also need to understand the difficulties that come with handling big data.
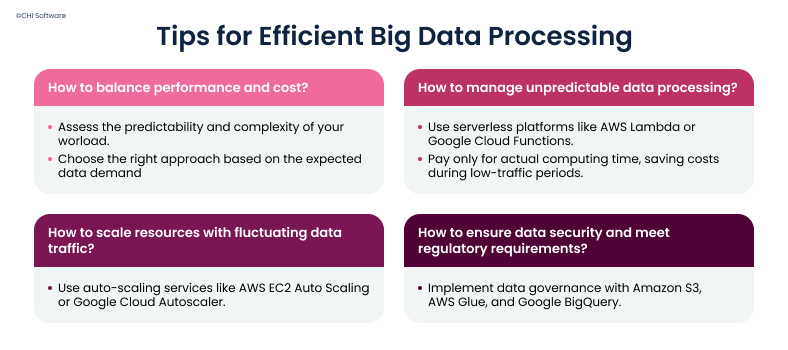
Here’s what it takes to handle big data efficiently.
Balancing Performance and Cost
How can you be sure that a big data setup is giving you the best possible performance without wasting money? It all comes down to understanding how predictable and complex your data workload is.
Serverless Processing for Unpredictable Workloads
In case you own an online store or any other event-driven business with unpredictable data processing needs, you should consider serverless processing. Why is that? You only pay for the computing time when your code works.
For example, if you only process data during a flash sale or customer registration, AWS Lambda or Google Cloud Functions should be your go-to platforms. You don’t need to keep these servers up and running all the time, which saves costs and reduces overheads. Also, you can automatically scale up functionality during high traffic times, and then scale it back down when traffic drops.
Logistics and Big Data: Use Cases & Proven Practices
Read more
Containerized Processing for Stable Workloads
If you manage large data sets regularly and your data processing is more predictable, containerized solutions Docker and Kubernetes give you the control and performance you need.
With containerized processing solutions, you always know what kind of workload is expected, so you can package your applications and the necessary dependencies into small and portable units called containers, and the software will run in the same way regardless of where it’s deployed.
How to Build a Scalable Data Warehouse Step by Step
Read more
The beauty of using containers is that you can proactively allocate resources based on your expected needs. For example, if you know you’ll be processing a large batch of data at certain times, you can set up containers for automatic scale-up to handle the increased load. Once the workload decreases, the system can scale back down.
Automatic Scaling with Cloud Solutions
At CHI Software, we often see companies overpaying for the infrastructure they don’t fully utilize, or struggling with performance bottlenecks when it’s time to scale up. Our advice? Let the cloud do the heavy lifting.
With the right setup, cloud tools can help you respond to demand before it becomes a problem. Here are a few steps to help automate your big data infrastructure scaling:
- Set up scaling rules: AWS, Google Cloud, Azure, and other cloud platforms allow you to define scaling rules based on CPU usage, memory usage, or query frequency;
- Use managed services: You may also use managed tools like Amazon EMR, Google Cloud Dataflow, or Azure Synapse, as they work by handling patching and performance optimization behind the scenes;
- Plan budgets and alerts: Cloud solutions let you track usage and enable spending alerts. CHI Software recommends setting soft and hard limits so you always know where your resources are going.
Organizations modernizing their infrastructure often rely on data migration consulting to move data securely from legacy systems to modern cloud environments.
Data Governance, Security, and Compliance
Proper data security and management are priorities for companies and can be one of the biggest challenges of big data in healthcare and finance due to the requirement of meeting regulatory standards.
Fortunately, cloud solutions like Amazon S3 offer built-in compliance features that make it easier to meet HIPAA and GDPR standards. Here are a few more tips to strengthen your data practices:
- Enable automatic versioning with tools like Delta Lake to track changes, maintain high data quality, and restore previous versions when needed. Automatic versioning is especially helpful for maintaining audit trails;
- Use cloud-based security tools that support compliance with industry regulations;
- Implement AWS IAM (Identity and Access Management) to define who can access specific data and enable multi-factor authentication (MFA) to protect sensitive information.
Without clear rules and accountability, big data projects may fail to deliver value, so data governance consulting becomes essential to secure quality and compliance across datasets.
How CHI Software Delivers Efficient Big Data Processing
At CHI Software, big data is an area where we have been delivering real, measurable value for over six years. We have more than 30 successful data projects under our belt. How did we do it? Only with the help of our people and approach. Around 70% of our data engineers are top-level specialists certified in Google Cloud, AWS, Azure, and Oracle.

Big data management and processing can be challenging – delegate the hardest tasks to our team.
Working with many different organizations’ data, we’ve noticed that one of the biggest challenges is bringing data together, as it is scattered across several platforms (if not dozens), may be stored in different formats, and is constantly changing.
All our technical powers are at your service – start your big data project with CHI Software!
Let's talk!
It is at this stage that companies usually turn to us for help. Our developers work to create customized pipelines that automatically collect, clean, and organize data from various sources: CRM systems, website analytics, and mobile applications. When everything is gathered in one place and properly structured, you will be able to finally see the changes:
- Reports that used to take hours to complete can now be done in minutes due to faster data processing;
- 50% less manual work thanks to automated data extraction and transformation;
- Working with the most up-to-date figures through real-time dashboards;
- Seamless scaling that allows you to manage growing data volumes without any problems.
These results have been felt by CHI Software’s clients from various industries: marketing, fintech, logistics, food technology, and healthcare. Regardless of the business domain, we develop a solution for each client that meets each company’s unique goals using the right combination of modern tools such as Apache Airflow, Power BI, dbt, and Azure Synapse.
Conclusion
Practical tips for tackling implementation challenges, choosing the right tech stack, and following proven strategies that work – we’ve provided all of this to help you understand how to deal with big data and turn those endless raw data streams into clear insights.
Efficient data management services help companies organize, monitor, and optimize their growing data assets, making insights more reliable and accessible.
And the payoff can be huge: better strategic decisions, improved control of operational processes, deeper customer understanding, and cost savings. There’s no reason to hesitate – turn your data into real business value with CHI Software today!
FAQs
-
How does CHI Software ensure scalability in big data solutions?

Scalability starts with choosing the proper big data processing techniques and architecture, and that's why:
- CHI Software's technical team builds systems using the Apache Spark and Hadoop frameworks, which can efficiently process large and growing amounts of data;
- Our engineers rely on AWS, Azure, and GCP cloud platforms to ensure your business scales automatically and resources remain flexible;
- We implement streaming processing, partitioning, and horizontal scaling to provide support through any unpredictable data spikes.
After deployment, CHI Software continuously monitors performance and adjusts resources to ensure that your systems scale smoothly, perform at peak capacity under any load, and meet all your requirements.
-
Can you help with real-time data processing and analytics?
Yes, of course. CHI Software develops data pipelines using Apache Kafka, Flink, and streaming services from major cloud providers. Solutions built with these tools allow your business to instantly receive, process, and respond to data.
-
How can I optimize costs while processing large amounts of data?
We suggest you consider:
- Adopting serverless technologies to pay only for the computing power you use;
- Using auto-scaling infrastructure, as it helps to adjust resources based on workload and avoid overprovisioning;
- Applying open-source tools that reduce the need for hardware and long-term resource commitments;
- Keeping valuable data readily accessible, while moving less-used information to the most cost-effective long-term storage options.
-
What security measures do you implement for data processing?
We follow strict security protocols to protect your data at every stage. Our measures include:
- Encryption during data transmission and storage,
- Role-based access control and identity management,
- Secure data masking, anonymization, and tokenization,
- Compliance with GDPR, HIPAA, and other industry standards.
In addition, the CHI Software team conducts regular audits to identify and prevent potential threats.
-
How long does it take to implement a big data solution for my company with CHI Software?
Your project's size, complexity, and specific requirements will determine the time required to implement a big data solution. Basic solutions typically take four weeks to implement, while more complex systems may require over eight weeks. Here are the key stages of big data implementation:
- Research phase (up to one week): Understanding your business goals and assessing data sources;
- Design and architecture (up to three weeks): Choosing big data characteristics, designing dashboards and data pipelines;
- Development and integration (up to six weeks): Developing system components and integration with other systems;
- Testing and optimization (up to three weeks): Checking data quality, conducting load testing, and refining big data analysis techniques;
- Deployment and training (up to two weeks): Deploying the system and training the team;
- Post-deployment support (ongoing): Updating and scaling your solution.
About the author
Sirojiddin is a seasoned Data Engineer and Cloud Specialist who’s worked across different industries and all major cloud platforms. Always keeping up with the latest IT trends, he’s passionate about building efficient and scalable data solutions. With a solid background in pre-sales and project leadership, he knows how to make data work for business.
Yana oversees relationships between departments and defines strategies to achieve company goals. She focuses on project planning, coordinating the IT project lifecycle, and leading the development process. In their role, she ensures accurate risk assessment and management, with business analysis playing a key part in proposals and contract negotiations.
Rate this article
55 ratings, average: 4.91 out of 5




